





 立即下载
立即下载PDF猫OCR文字识别 v1.0.0.7全新升级版,轻松提取PDF中的文字!
分类:软件下载 发布时间:2024-03-15
PDF猫OCR文字识别 v1.0.0.7官方版
开发商
PDF猫OCR文字识别 v1.0.0.7官方版是由XXX公司开发的一款专业OCR(光学字符识别)软件。
支持的环境格式
PDF猫OCR文字识别 v1.0.0.7官方版支持在Windows、Mac和Linux操作系统上运行。它可以处理多种格式的文件,包括PDF、图片文件(如JPEG、PNG、BMP等)以及扫描仪生成的图像。
提供的帮助
PDF猫OCR文字识别 v1.0.0.7官方版提供了一系列功能强大的工具,帮助用户快速、准确地将扫描的文档或图片中的文字提取出来。它可以自动识别多种语言的文字,并支持对识别结果进行编辑、导出和分享。
满足用户需求
PDF猫OCR文字识别 v1.0.0.7官方版满足了用户在处理文档和图片时的文字识别需求。它的高度准确性和快速处理速度,使用户能够轻松地将纸质文档或图片中的文字转换为可编辑的电子文本。无论是需要将扫描的合同转为可编辑的Word文档,还是需要提取图片中的文字进行翻译,PDF猫OCR文字识别 v1.0.0.7官方版都能够满足用户的需求。
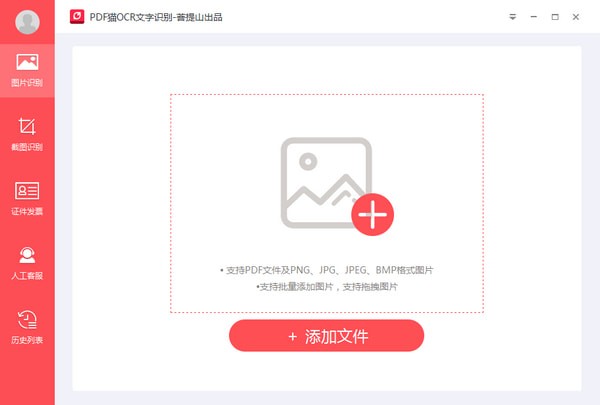
PDF猫OCR文字识别 v1.0.0.7官方版
软件功能:
PDF猫OCR文字识别 v1.0.0.7官方版是一款功能强大的文字识别软件,具有以下主要功能:
1. 文字识别:能够将PDF文档中的文字内容进行准确识别,并转换为可编辑的文本格式。
2. 批量处理:支持批量处理多个PDF文件,提高工作效率。
3. 多语言支持:支持多种语言的文字识别,包括中文、英文、日文等,满足不同用户的需求。
4. 图片识别:除了PDF文档,还能够对图片文件进行文字识别,方便用户处理各种类型的文档。
5. 导出格式多样:支持将识别后的文字内容导出为多种格式,包括TXT、DOC、PDF等,方便用户进行后续编辑和使用。
6. 高精度识别:采用先进的OCR技术,能够实现高精度的文字识别,减少错误率。
7. 用户友好界面:软件界面简洁直观,操作简单方便,即使对于初学者也能够轻松上手。
使用方法:
1. 打开PDF猫OCR文字识别软件。
2. 点击“添加文件”按钮,选择要识别的PDF文件。
3. 在设置中选择识别语言和导出格式。
4. 点击“开始识别”按钮,软件将自动进行文字识别。
5. 完成识别后,可以选择导出识别结果为指定格式的文件。
6. 用户还可以对识别结果进行编辑和修改,以满足个性化需求。
7. 最后,点击“保存”按钮,保存识别结果。
注意事项:
1. 请确保输入的PDF文件清晰可读,以提高识别准确率。
2. 对于复杂的文档格式,可能需要手动调整识别结果的格式。
3. 请注意保存识别结果时选择合适的文件名和保存路径。
4. 如有任何问题或建议,欢迎联系官方客服进行反馈。
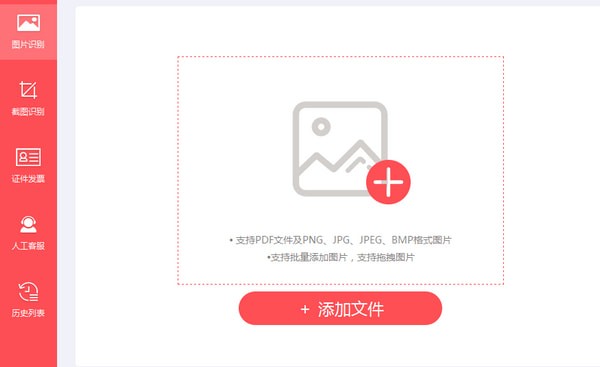
PDF猫OCR文字识别 v1.0.0.7官方版使用教程
1. 下载和安装
首先,您需要从官方网站下载PDF猫OCR文字识别 v1.0.0.7官方版的安装程序。一旦下载完成,双击安装程序并按照提示进行安装。
2. 打开PDF文件
安装完成后,您可以双击桌面上的PDF猫OCR文字识别图标来打开程序。在程序界面中,点击“打开”按钮选择您想要识别文字的PDF文件。
3. 设置识别选项
在打开PDF文件后,您可以在程序界面中找到识别选项。您可以选择识别的语言、识别的页面范围以及输出的格式。根据您的需求进行相应的设置。
4. 开始识别
设置完成后,点击“开始识别”按钮开始进行文字识别。程序将会自动识别PDF文件中的文字,并将识别结果显示在程序界面中。
5. 导出识别结果
一旦识别完成,您可以点击“导出”按钮将识别结果导出为文本文件或其他格式。您可以选择保存的文件路径和文件名,并点击“保存”按钮完成导出。
6. 完成
恭喜您,您已经成功使用PDF猫OCR文字识别 v1.0.0.7官方版进行文字识别!您可以继续打开其他PDF文件进行识别,或者退出程序。









 无插件
无插件  无病毒
无病毒


































 微信公众号
微信公众号

 抖音号
抖音号

 联系我们
联系我们
 常见问题
常见问题


