


-
通用新闻网页抽取器v0.2.6官方版:提升抽取效果,轻松获取新闻正文
-

- 系统大小:15KB
- 更新时间:2023-07-26
- 软件类型:国产软件
- 授权方式:免费软件
- 系统语言:简体中文
- 星级:
GeneralNewsExtractor(新闻网页正文通用抽取器) v0.2.6官方版
软件简介
GeneralNewsExtractor是一款功能强大的新闻网页正文通用抽取器,旨在帮助用户从各种新闻网页中提取出正文内容。该软件通过智能算法和自然语言处理技术,能够准确、高效地抽取出新闻网页中的正文部分,帮助用户快速获取所需信息。
开发商
GeneralNewsExtractor由一支专业的开发团队开发,致力于提供高质量的文本抽取解决方案。他们拥有丰富的经验和技术专长,确保软件的稳定性和准确性。
支持的环境格式
GeneralNewsExtractor支持多种环境格式,包括Windows、Mac和Linux操作系统。用户可以根据自己的需求选择适合的环境进行安装和使用。
提供的帮助
GeneralNewsExtractor提供了详细的帮助文档和技术支持,帮助用户快速上手并解决在使用过程中遇到的问题。用户可以通过阅读文档或联系开发团队获取所需的帮助和支持。
满足用户需求
GeneralNewsExtractor通过准确、高效地抽取新闻网页的正文内容,满足了用户获取新闻信息的需求。用户可以通过该软件快速获取新闻网页中的关键信息,节省时间和精力。同时,软件提供的多种环境格式和详细的帮助文档,使用户能够根据自己的需求进行安装和使用,并在使用过程中得到及时的支持和帮助。
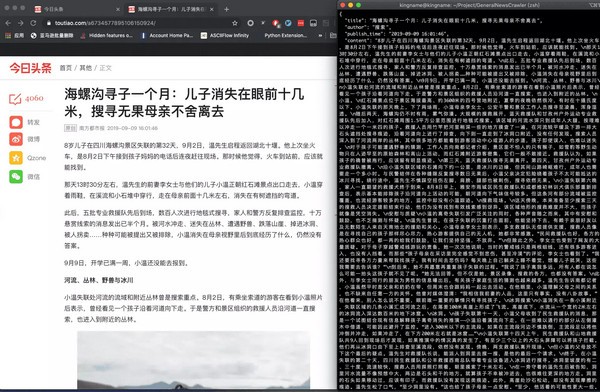
GeneralNewsExtractor(新闻网页正文通用抽取器) v0.2.6官方版
软件功能:
GeneralNewsExtractor是一款用于从新闻网页中提取正文内容的通用抽取器。它具有以下主要功能:
1. 自动识别新闻网页:GeneralNewsExtractor能够自动识别新闻网页,并提取其中的正文内容。无论是国内还是国际的新闻网站,该软件都能有效地提取出新闻正文。
2. 去除噪音和广告:该抽取器能够智能地去除新闻网页中的噪音和广告,只保留与新闻内容相关的部分。用户可以获得干净、整洁的新闻正文,提高阅读体验。
3. 支持多种语言:GeneralNewsExtractor支持多种语言的新闻网页抽取。无论是中文、英文、法文、德文还是其他语言的新闻网页,该软件都能准确地提取出正文内容。
4. 提供可定制化选项:用户可以根据自己的需求进行定制化设置。软件提供了一系列选项,如是否提取图片、是否提取评论等,用户可以根据需要进行选择。
5. 高效且准确:GeneralNewsExtractor采用了先进的算法和模型,能够高效且准确地提取新闻正文。无论是新闻网页的结构复杂与否,该软件都能够应对,并提供准确的结果。
使用方法:
使用GeneralNewsExtractor非常简单,只需按照以下步骤进行操作:
1. 打开GeneralNewsExtractor软件。
2. 将需要提取正文的新闻网页链接粘贴到软件界面的输入框中。
3. 点击“提取”按钮,软件将自动识别并提取出新闻网页的正文内容。
4. 用户可以选择将提取结果保存为文本文件或直接复制到剪贴板中。
5. 完成提取后,用户可以继续提取其他新闻网页的正文内容,或者退出软件。
注意事项:
在使用GeneralNewsExtractor时,需要注意以下事项:
1. 请确保输入的新闻网页链接正确无误,否则可能无法正确提取正文内容。
2. 由于新闻网页的结构多样化,软件可能无法对所有网页都进行准确的提取。在遇到提取错误的情况时,建议尝试调整软件的定制化选项,以获得更好的提取结果。
3. 请遵守相关法律法规,在使用GeneralNewsExtractor提取新闻正文时,不要侵犯他人的版权和隐私。
总之,GeneralNewsExtractor是一款功能强大、易于使用的新闻网页正文抽取器。它能够帮助用户快速、准确地提取新闻网页的正文内容,提高阅读效率和体验。
GeneralNewsExtractor(新闻网页正文通用抽取器) v0.2.6官方版 使用教程
简介
GeneralNewsExtractor是一款开源的Python库,用于从新闻网页中提取正文内容。它可以自动识别网页结构,并根据一系列规则抽取出新闻正文,过滤掉广告、导航栏等无关内容,提供给用户干净、易读的新闻正文。
安装
要使用GeneralNewsExtractor,首先需要安装Python和相关依赖库。可以通过以下命令安装:
pip install GeneralNewsExtractor使用方法
使用GeneralNewsExtractor非常简单,只需按照以下步骤进行:
- 导入GeneralNewsExtractor库:
- 创建GeneralNewsExtractor对象:
- 调用extract方法提取新闻正文:
- 输出提取到的新闻正文:
from GeneralNewsExtractor import GeneralNewsExtractorextractor = GeneralNewsExtractor()content = extractor.extract(html)其中,html是新闻网页的HTML源代码,可以是字符串或文件路径。
print(content)示例
以下是一个完整的示例,演示如何使用GeneralNewsExtractor提取新闻正文:
from GeneralNewsExtractor import GeneralNewsExtractor# 创建GeneralNewsExtractor对象extractor = GeneralNewsExtractor()# 读取新闻网页的HTML源代码with open('news.html', 'r', encoding='utf-8') as f: html = f.read()# 提取新闻正文content = extractor.extract(html)# 输出提取到的新闻正文print(content)注意事项
在使用GeneralNewsExtractor时,需要注意以下几点:
- GeneralNewsExtractor对于不同的新闻网页可能有不同的效果,需要根据实际情况进行调整。
- 如果提取结果不理想,可以尝试调整GeneralNewsExtractor的一些参数,如正文长度阈值、标题长度阈值等。
- GeneralNewsExtractor可能无法处理一些特殊的新闻网页,如动态加载内容、使用JavaScript渲染的网页等。
希望以上教程能帮助您快速上手使用GeneralNewsExtractor提取新闻正文。
热门系统
-
 Win10激活工具_暴风永久激活win10/win8/win7系统通用
Win10激活工具_暴风永久激活win10/win8/win7系统通用
-
 windows系统之家一键重装V4.7官方版
windows系统之家一键重装V4.7官方版
-
 系统之家一键重装系统软件V11.5.44.1230
系统之家一键重装系统软件V11.5.44.1230
-
 小白一键重装系统V12.6.48.1920官方版
小白一键重装系统V12.6.48.1920官方版
- Win10激活工具_暴风永久激活win10/win8/win7系统通用 05-16
- windows系统之家一键重装V4.7官方版 05-27
- 系统之家一键重装系统软件V11.5.44.1230 11-01
- 小白一键重装系统V12.6.48.1920官方版 10-18
- 魔法猪系统重装大师 V11.5.47.1530 12-13
- 装机吧U盘制作工具V11.5.47.1530 12-13
 萝卜家园Ghost Win7 64位纯净版系统下载 v1903
萝卜家园Ghost Win7 64位纯净版系统下载 v1903 【免费版】拓
【免费版】拓 免费版域名全
免费版域名全 【全新升级】
【全新升级】 免费下载:二维
免费下载:二维 免费下载:图生
免费下载:图生 点击宝 v2.0.
点击宝 v2.0. 蓝天表单图片
蓝天表单图片 全新升级!立即
全新升级!立即 imeight(HTML
imeight(HTML 【全新升级】
【全新升级】 极兔速递工具
极兔速递工具 粤公网安备 44130202001061号
粤公网安备 44130202001061号